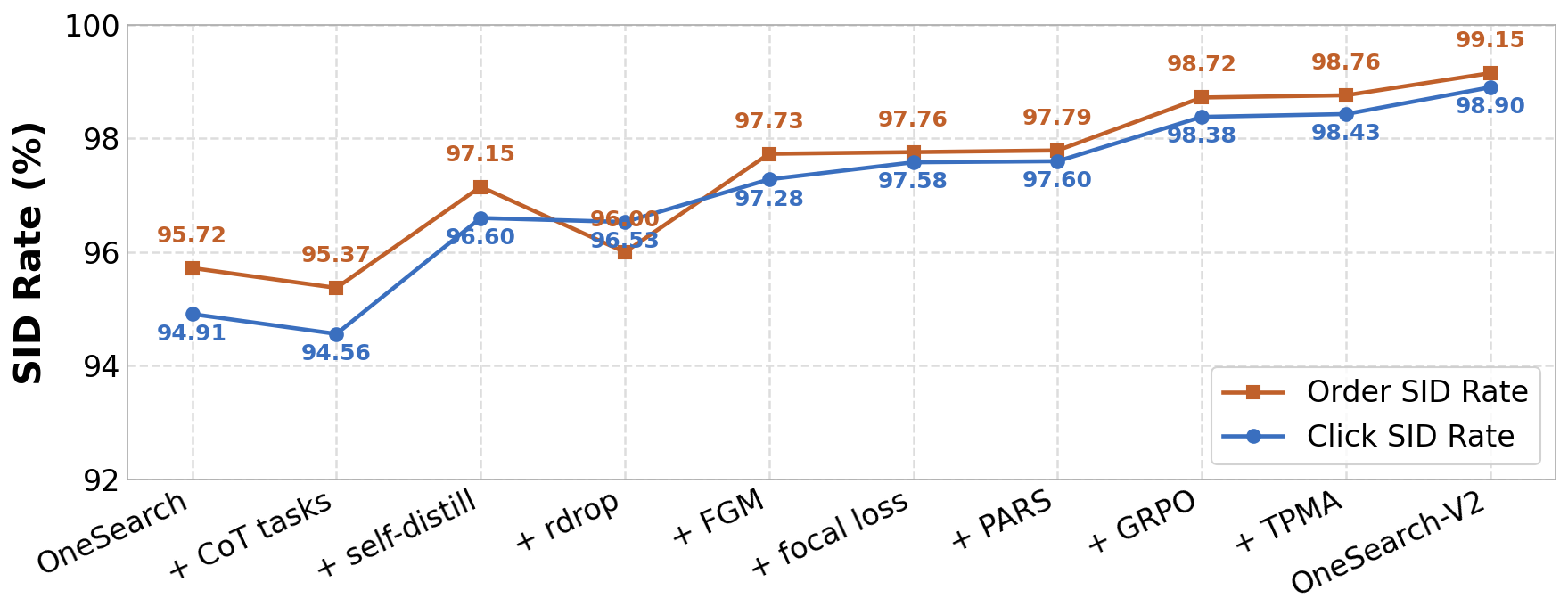
🔄 OneSearch-V1 vs. V2
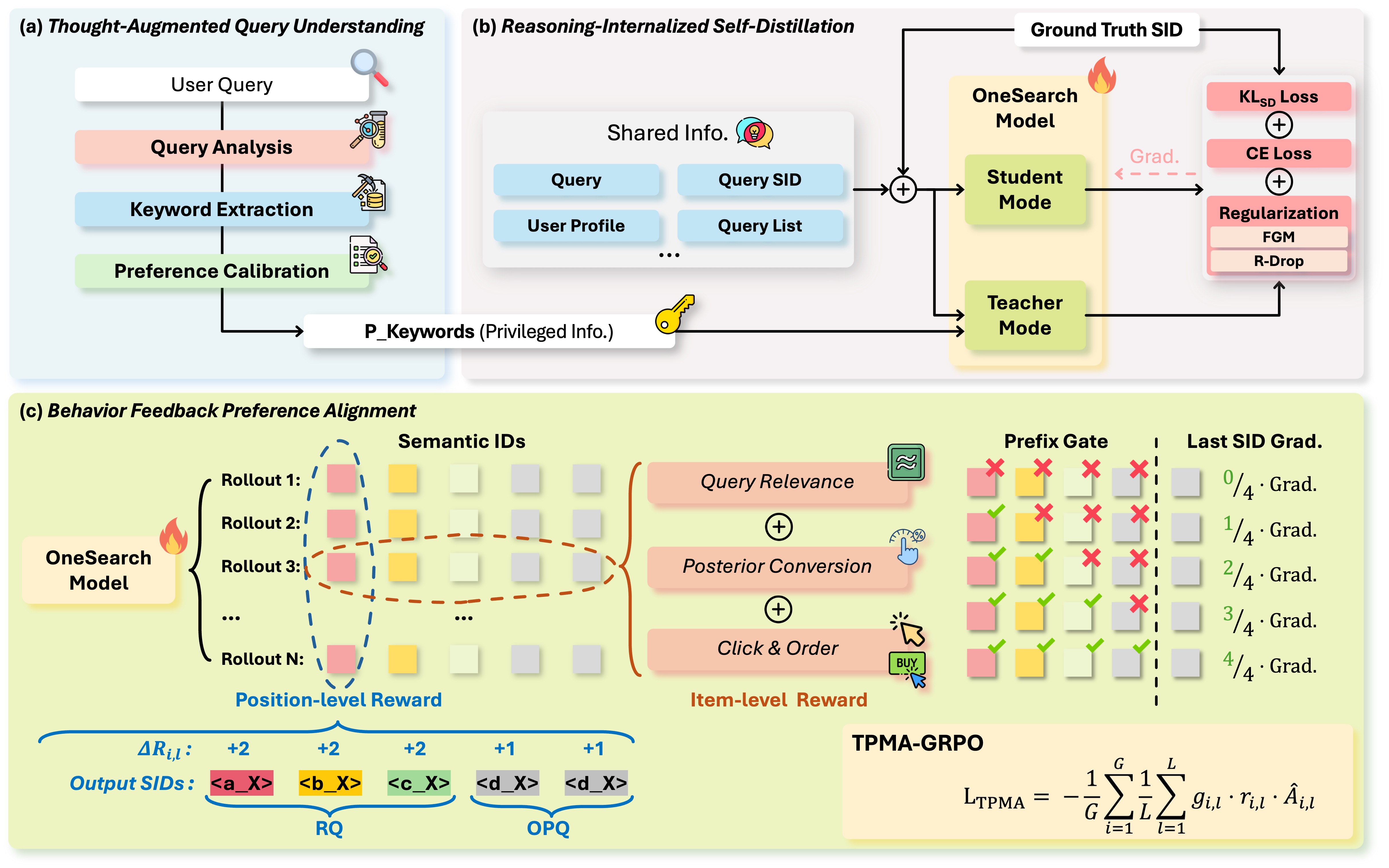
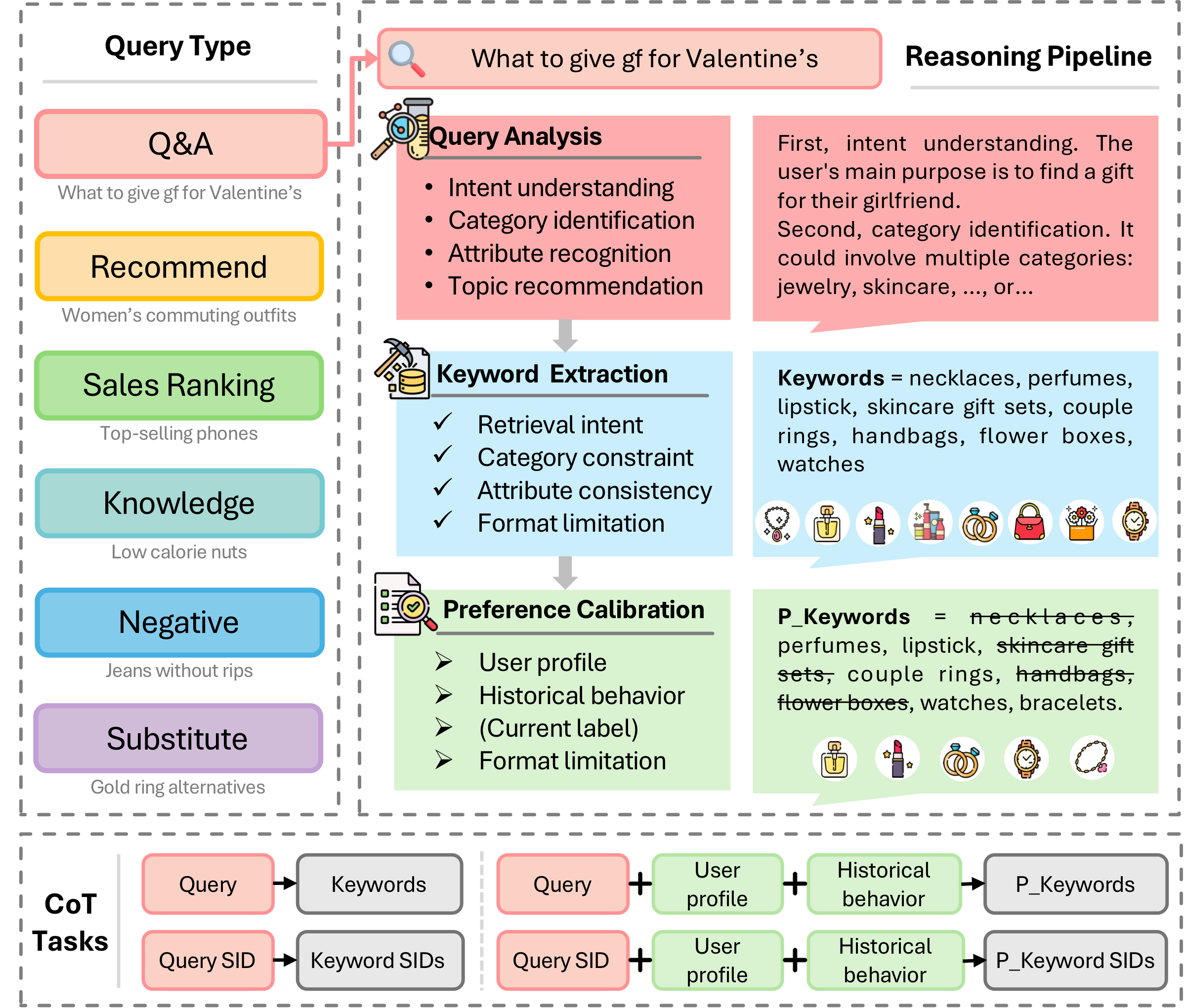
OneSearch-V2 extends the generative search framework with thought-augmented query understanding, reasoning-internalized self-distillation, and behavior feedback preference alignment.
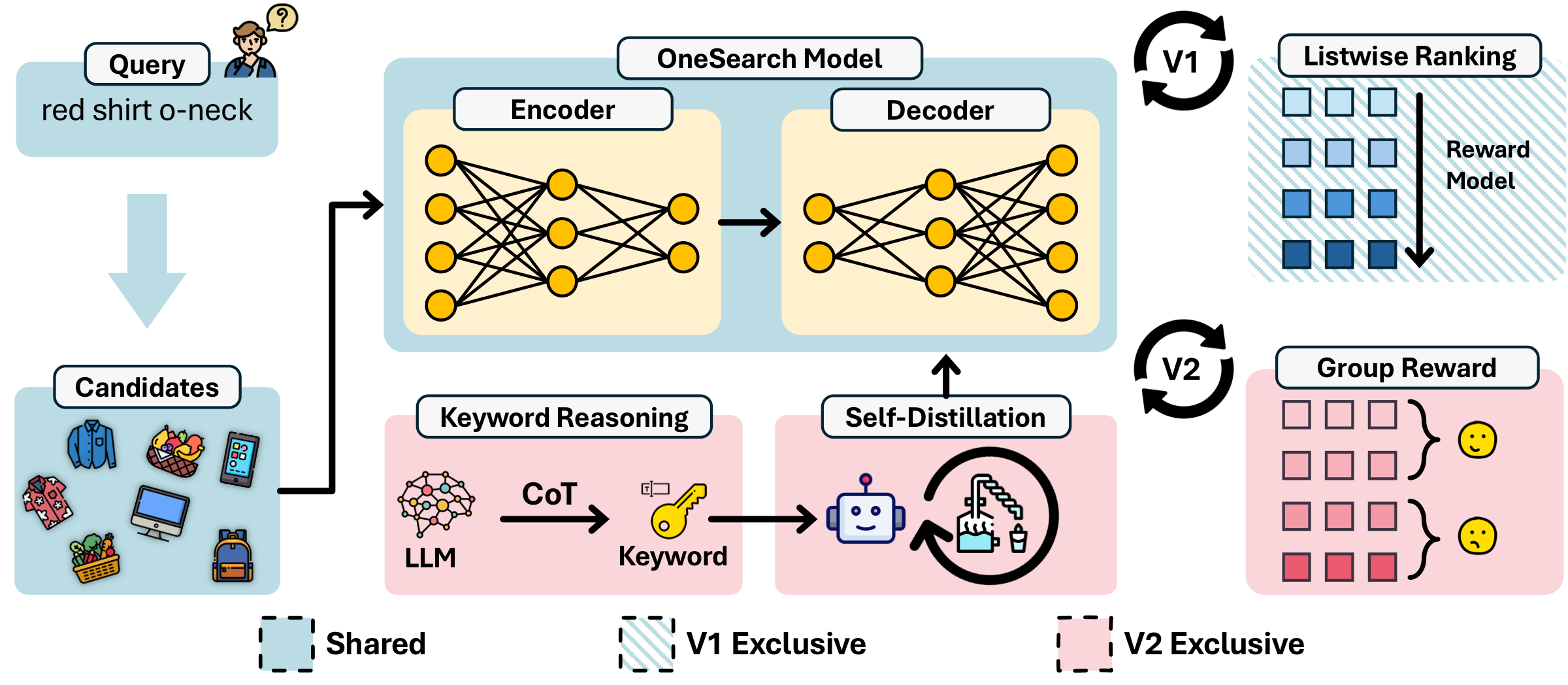
Figure 1: OneSearch-V2 vs. V1. OneSearch-V2 extends the generative search framework with three key innovations: thought-augmented query understanding, reasoning-internalized self-distillation, and behavior feedback preference alignment.